【Python】新闻文本分类

【Python】新闻文本分类
客怎眠qvq前言
一个很粗糙的新闻文本分类项目,解决中国软件杯第九届新闻文本分类算法的问题,记录了项目的思路及问题解决方法
后续会进一步改进,包括:
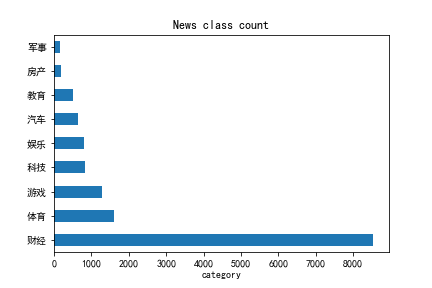
- 丰富训练集的数据,避免军事类、房产类、体育类的新闻数据过少,影响精度
- 改用上限更高的Bert模型
- 优化exe文件的页面,使其能够分别处理识别短文本和excel文件
项目源码:https://github.com/bluehyssopu/NewSort
项目问题链接:http://cnsoftbei.com/plus/view.php?aid=599
- code
- -pycache- ---pyinstaller 打包生成的文件
- build ---pyinstaller 打包生成的文件
- dist ---pyinstaller 打包生成的文件(内有 软件test2.exe 可运行)
- showTest.ipynb ---展示测试集处理的脚本
- showTrain.ipynb ---展示训练集处理的脚本
- test.py ---测试所用的py文件 可跳过
- test2.py ---项目最终源代码
- test2.spec ---pyinstaller 打包生成的文件
- data
- hit_stopwords.txt ---哈工大停词表
- test_set.csv ---处理好的测试集数据
- train_set.csv ---处理好的训练集数据
- type.xlsx ---原测试集数据的类别sheet
- image ---项目的部分运行结果截图
- rootData ---数据清洗前的源数据
- RemdMe.md ---项目文件说明
```运行dist目录下的test2.exe即可运行程序
选择文件dist/data/type.xlsx 点击确认 即可运行将预测结果写入 至type.xlsx
操作的过程如下:
查看源数据
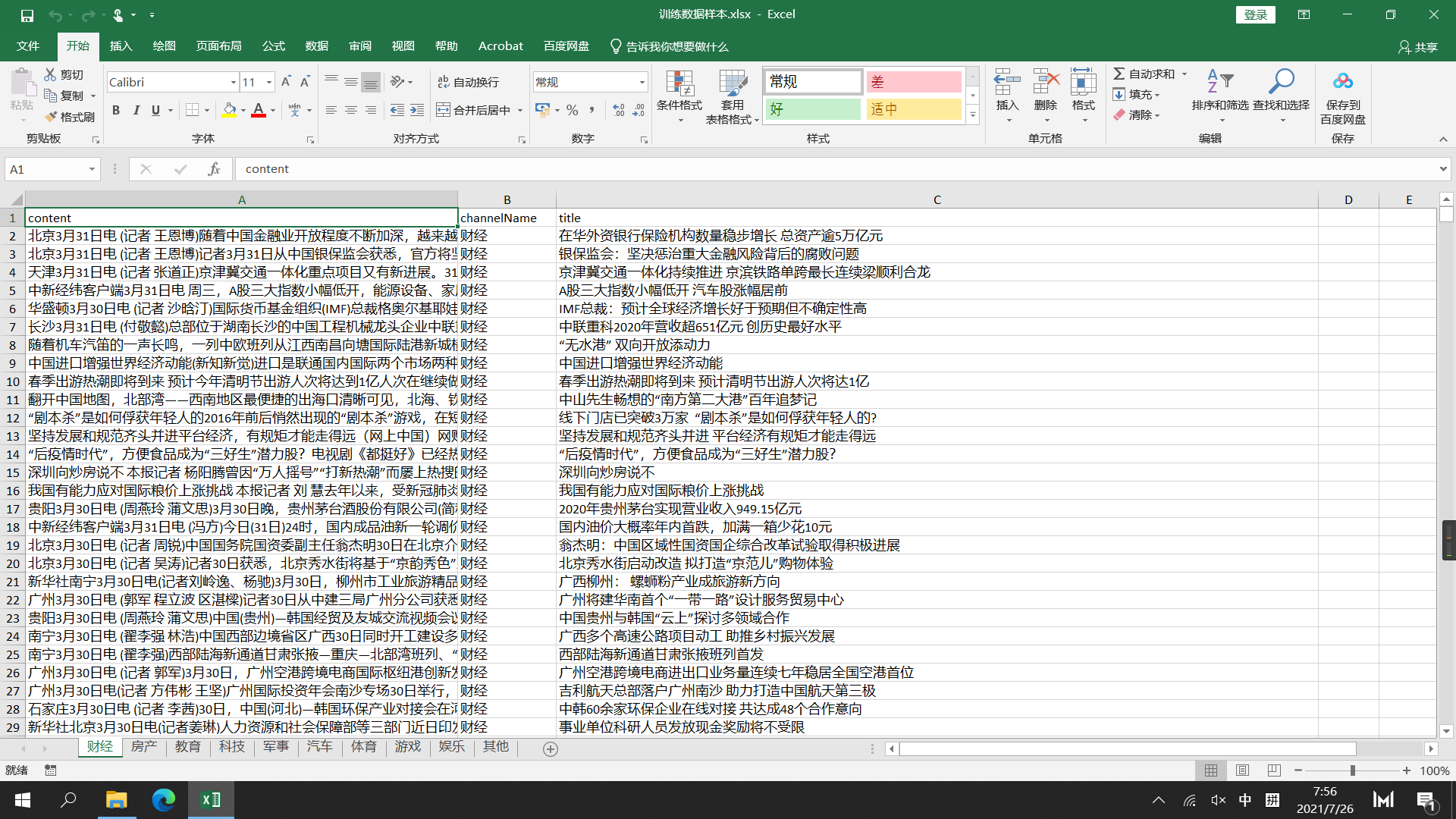
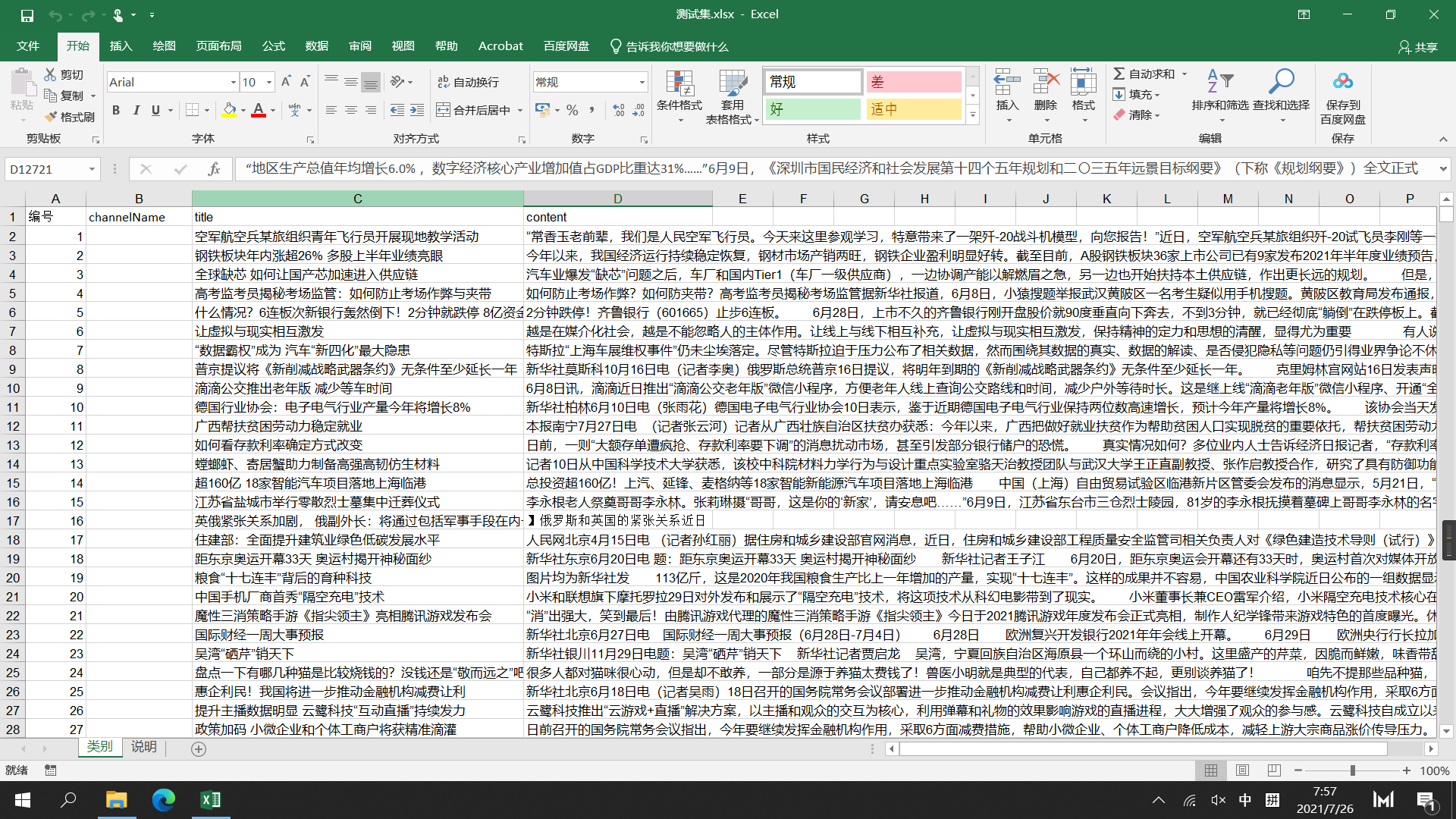
可以明显地看出:
- 源数据(训练)包括新闻标题 内容 和新闻的类别 —- 以下称为 根训练集
- 测试集 包括 测试的编号 新闻标题 新闻内容 —- 以下称为 type.xlsx
需要将预测的结果写入channelName这一列中
为了方便我们进行清洗数据 训练
将跟训练集的所有sheet(共九个 其他栏为空)导出为csv 并合并为 train_root.csv
具体过程如下:
导出
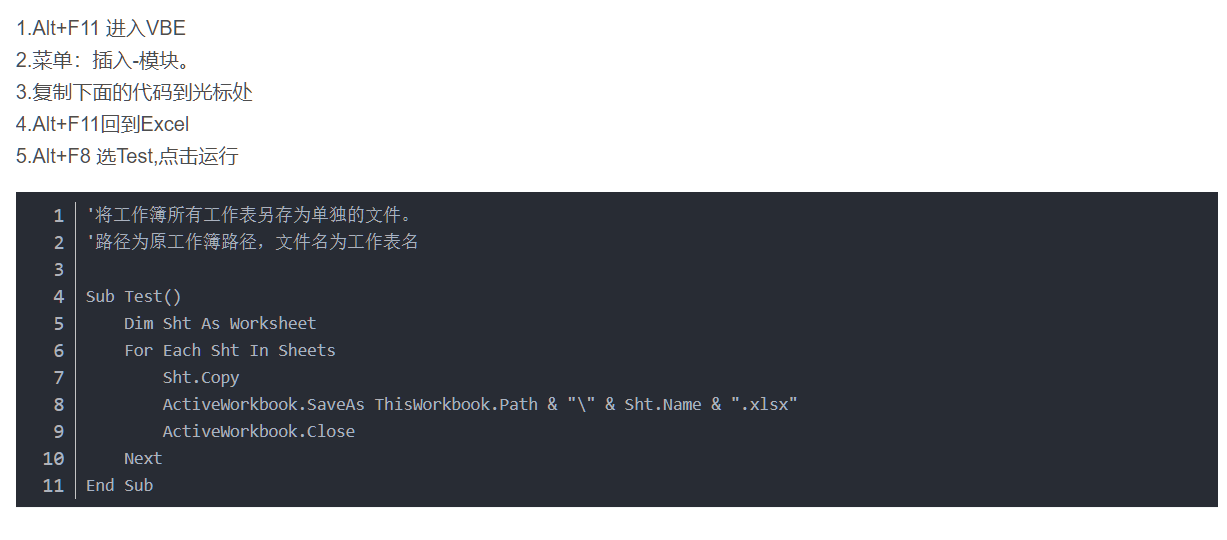
1 | Sub Test() |
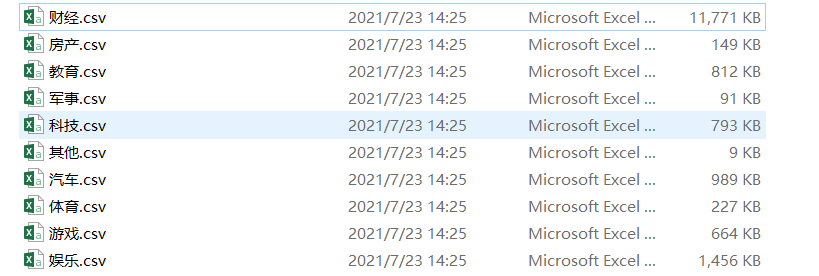
合并
- cmd命令行 切换到 所在的目录
copy *.csv train_copy.csv
输出测试
1 | import pandas as pd |

统计
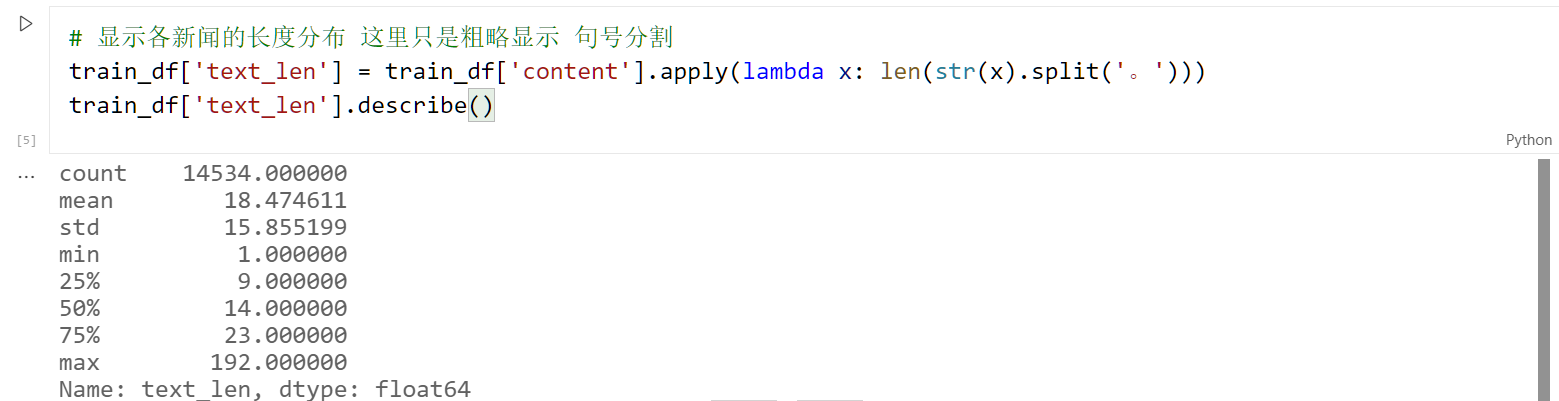
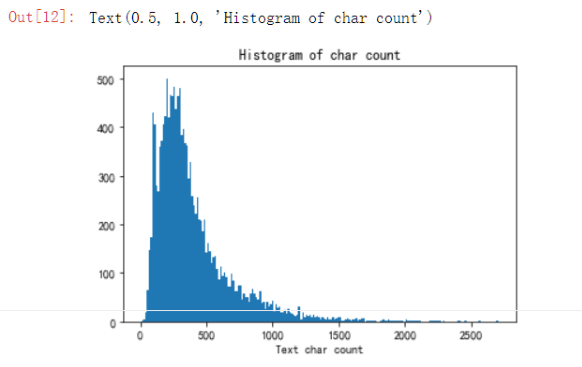
1 | # 显示各新闻的长度分布 这里只是粗略显示 句号分割 |
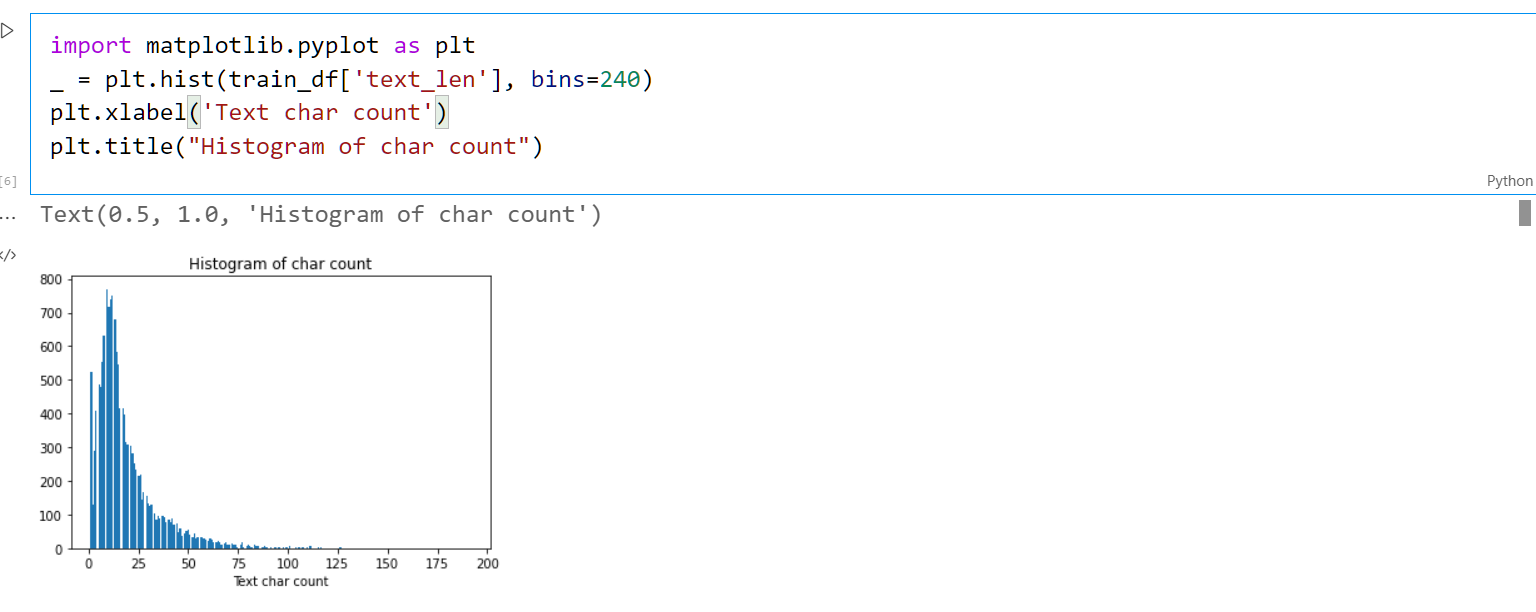
1 | # 统计文本长度 生成直方图 |
数据可视分析 清洗处理
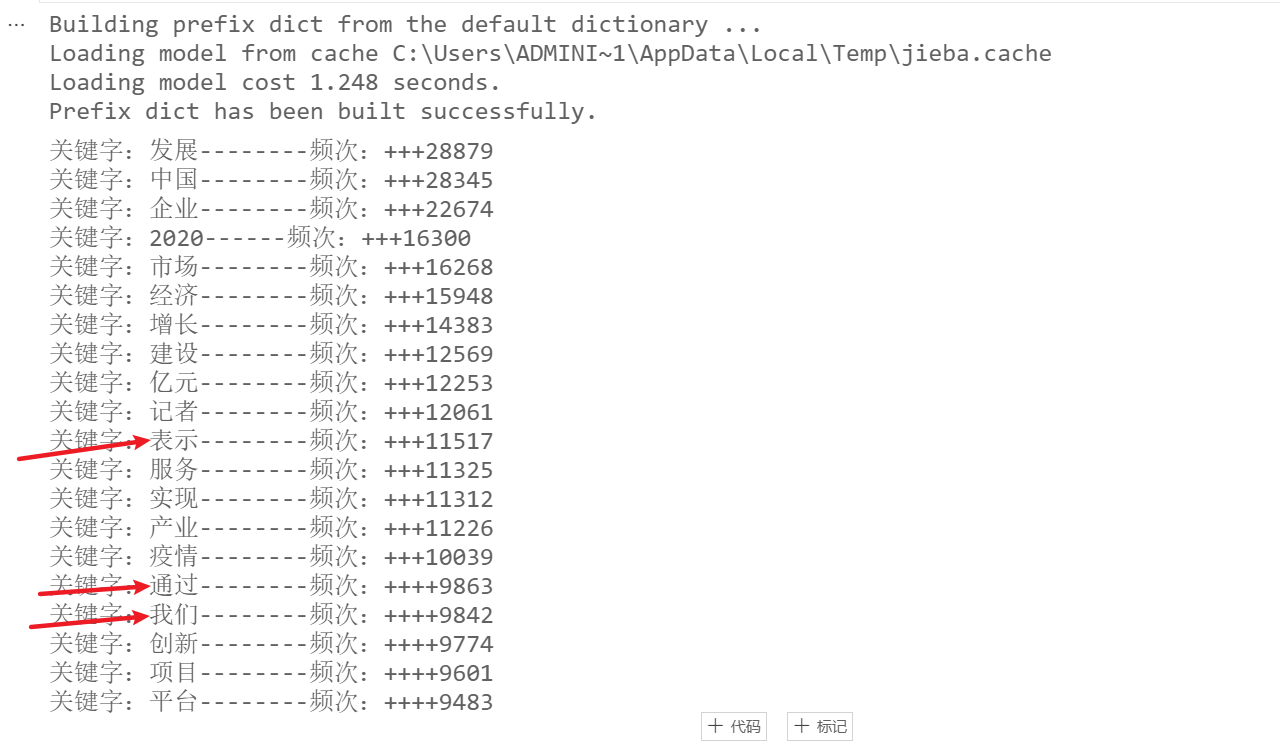
词频统计
加载停用词
1 | with open("/data/hit_stopwords.txt", 'r', encoding='utf-8') as f: |
生成词云
- 检查无用词 说明清洗有效
| 清洗前 | 清洗后 |
|---|---|
 |
 |
再次检验
写入
- 将清洗好的数据写入到 train_set.csv中 作为机器学习的训练集 —- 下称为训练集
1 | import csv |
训练
- 简单读取 验证训练集的内容
- 训练模型
1 | # Count Vectors + RidgeClassifier |
预测结果
- 对预测集进行和训练集一样的处理
- 调用模型 得到pre_val (预测结果 类型为list)
- 写入 type.xlsx中即可

喜欢这篇文章的人也看了






评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果





