【Bug周刊】Vol.8

【Bug周刊】Vol.8
客怎眠qvq前言
最近开发中遇到很多相同的问题,下意识去翻自己的历史记录,但又没能快速定位。我的trilium一直用来记录自己的周报和相关教程,对于常见的bug和修复方案也找不到合适的地方,只能穿插在日报的历史中,随时间沉没。无意间翻到子舒的奇趣周刊,Bug周刊也由此而生。
过完年了?艹我不是刚放假吗
雪花算法
问题描述
业务核心逻辑调整,原系统数据库的主键为uuid,随着业务数据的增大,数据库插入、修改的开销越来越大,uuid的无序性对B+树有很大的影响,且有重复风险。
同时当前系统需要推送数据至下游,下游系统的主键是雪花id,调整主键有利于性能的提升,方便下游存储。

解决方案
当前系统采用微服务架构,调整的逻辑仅为系统模块,为了后续其他模块在有需求时也可以直接调用,决定将雪花算法的配置注入放到 common 模块中,使用 redis 存储各个模块对应的 workId,同时使用 map 管理所有模块所有节点(pod)对应的 id,避免重复。
config 包 SnowflakeConfig 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
public class SnowflakeConfig {
private SnowflakeRedisUtils snowflakeRedisUtils;
private String serviceName;
private static final String WORKER_ID_COUNTER = "snowflake:worker:global:counter";
private static final String WORKER_ID_REGISTRY = "snowflake:worker:%s:registry";
private static final String WORKER_ID_LOCK = "snowflake:worker:%s:lock";
private static final String ACTIVE_WORKER_IDS = "snowflake:worker:active:map";
private static final long MAX_WORKER_ID = 31;
private Long currentWorkerId;
public void init() {
// 在应用关闭时释放workerId
Runtime.getRuntime().addShutdownHook(new Thread(this::releaseWorkerId));
}
public SnowflakeIdGenerator snowflakeIdGenerator() {
Long workerId = getWorkerId();
return new SnowflakeIdGenerator(workerId, 1);
}
private Long getWorkerId() {
if (currentWorkerId != null) {
return currentWorkerId;
}
boolean lockAcquired = false;
try {
// 尝试获取分布式锁
String lockKey = String.format(WORKER_ID_LOCK, serviceName);
lockAcquired = Boolean.TRUE.equals(snowflakeRedisUtils.setIfAbsent(lockKey, "LOCK", 10));
if (!lockAcquired) {
throw new RuntimeException("无法获取分布式锁");
}
// 从计数器获取新的 workerId
Long newWorkerId = null;
int attempts = 0;
final int MAX_ATTEMPTS = 32;
while (attempts < MAX_ATTEMPTS) {
Long candidateId = snowflakeRedisUtils.increment(WORKER_ID_COUNTER);
// 如果超过最大值,重置计数器
if (candidateId > MAX_WORKER_ID) {
snowflakeRedisUtils.del(WORKER_ID_COUNTER);
candidateId = snowflakeRedisUtils.increment(WORKER_ID_COUNTER);
}
// 检查这个 workerId 是否已被使用
String activeKey = String.valueOf(candidateId);
if (!snowflakeRedisUtils.hHasKey(ACTIVE_WORKER_IDS, activeKey)) {
newWorkerId = candidateId;
// 将新的 workerId 添加到活跃映射中
snowflakeRedisUtils.hset(ACTIVE_WORKER_IDS, activeKey, serviceName);
break;
}
attempts++;
}
if (newWorkerId == null) {
throw new RuntimeException("无法分配可用的 workerId,所有 workerId 已被占用");
}
// 注册 workerId (保持服务级别的注册,用于心跳检测)
String registryKey = String.format(WORKER_ID_REGISTRY + ":%d", serviceName, newWorkerId);
snowflakeRedisUtils.set(registryKey, "ACTIVE", 5, TimeUnit.MINUTES);
currentWorkerId = newWorkerId;
// 记录分配的workerId
log.info("服务[{}]成功分配 workerId: {}", serviceName, newWorkerId);
return newWorkerId;
} finally {
if (lockAcquired) {
// 释放分布式锁
String lockKey = String.format(WORKER_ID_LOCK, serviceName);
snowflakeRedisUtils.del(lockKey);
}
}
}
// 每180秒执行一次心跳,注册缓存5分钟
public void startHeartbeat() {
try {
if (currentWorkerId == null) {
log.info("当前服务[{}]未初始化workerId,跳过心跳", serviceName);
return;
}
String registryKey = String.format(WORKER_ID_REGISTRY + ":%d", serviceName, currentWorkerId);
log.info("准备续期注册信息,key={}", registryKey);
boolean success = snowflakeRedisUtils.set(registryKey, "ACTIVE", 5, TimeUnit.MINUTES);
// 清理已过期的workerId映射
cleanupExpiredWorkerIds();
// 更新当前服务的活跃映射
snowflakeRedisUtils.hset(ACTIVE_WORKER_IDS, String.valueOf(currentWorkerId), serviceName);
if (success) {
log.info("❤️ 服务[{}]的workerId[{}]续期成功,TTL=5min,key={}", serviceName, currentWorkerId, registryKey);
} else {
log.info("⚠️ 服务[{}]的workerId[{}]续期失败,key={}", serviceName, currentWorkerId, registryKey);
}
} catch (Exception e) {
log.info("服务[{}]的workerId[{}]续期异常", serviceName, currentWorkerId, e);
}
}
// 清理已过期的workerId映射
private void cleanupExpiredWorkerIds() {
try {
// 获取当前所有活跃映射
Map<Object, Object> activeMap = snowflakeRedisUtils.hmget(ACTIVE_WORKER_IDS);
if (activeMap == null || activeMap.isEmpty()) {
return;
}
// 检查每个workerId的注册key是否存在
for (Map.Entry<Object, Object> entry : activeMap.entrySet()) {
String workerId = entry.getKey().toString();
String service = entry.getValue().toString();
String registryKey = String.format(WORKER_ID_REGISTRY + ":%d", service, Long.parseLong(workerId));
// 如果注册key不存在,说明该workerId已过期,从映射中删除
if (!snowflakeRedisUtils.hasKey(registryKey)) {
snowflakeRedisUtils.hdel(ACTIVE_WORKER_IDS, workerId);
log.info("清理过期的workerId映射:workerId={}, service={}", workerId, service);
}
}
} catch (Exception e) {
log.warn("清理过期workerId映射异常", e);
}
}
// 在应用关闭时释放workerId
private void releaseWorkerId() {
if (currentWorkerId != null) {
try {
// 删除注册信息
String registryKey = String.format(WORKER_ID_REGISTRY + ":%d", serviceName, currentWorkerId);
snowflakeRedisUtils.del(registryKey);
// 从活跃映射中移除
snowflakeRedisUtils.hdel(ACTIVE_WORKER_IDS, String.valueOf(currentWorkerId));
log.info("服务[{}]释放 workerId: {}", serviceName, currentWorkerId);
} catch (Exception e) {
log.error("释放 workerId 失败", e);
}
}
}
}
util 包 SnowflakeIdGenerator 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87public class SnowflakeIdGenerator {
// 开始时间截 (2024-01-01)
private final long twepoch = 1704067200000L;
// 机器id所占的位数
private final long workerIdBits = 5L;
// 数据标识id所占的位数
private final long datacenterIdBits = 5L;
// 支持的最大机器id
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 支持的最大数据标识id
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 序列在id中占的位数
private final long sequenceBits = 12L;
// 机器ID向左移12位
private final long workerIdShift = sequenceBits;
// 数据标识id向左移17位
private final long datacenterIdShift = sequenceBits + workerIdBits;
// 时间截向左移22位
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// 生成序列的掩码
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
// 工作机器ID(0~31)
private long workerId;
// 数据中心ID(0~31)
private long datacenterId;
// 毫秒内序列(0~4095)
private long sequence = 0L;
// 上次生成ID的时间截
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("Worker Id can't be greater than " + maxWorkerId + " or less than 0");
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("Datacenter Id can't be greater than " + maxDatacenterId + " or less than 0");
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
}
util 包 SnowflakeRedisUtils 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
public class SnowflakeRedisUtils {
private static final Logger log = LoggerFactory.getLogger(SnowflakeRedisUtils.class);
private RedisTemplate<Object, Object> redisTemplate;
public SnowflakeRedisUtils(RedisTemplate<Object, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean hasKey(String key) {
try {
return this.redisTemplate.hasKey(key);
} catch (Exception var3) {
log.error(var3.getMessage(), var3);
return false;
}
}
public boolean setIfAbsent(String key, Object value, long time) {
try {
return Boolean.TRUE.equals(this.redisTemplate.opsForValue().setIfAbsent(key, value, time, TimeUnit.SECONDS));
} catch (Exception var6) {
log.error(var6.getMessage(), var6);
return false;
}
}
public void del(String... keys) {
if (keys != null && keys.length > 0) {
if (keys.length == 1) {
boolean result = this.redisTemplate.delete(keys[0]);
log.info("--------------------------------------------");
log.info("删除缓存:" + keys[0] + ",结果:" + result);
log.info("--------------------------------------------");
} else {
Set<Object> keySet = new HashSet();
String[] var3 = keys;
int var4 = keys.length;
for(int var5 = 0; var5 < var4; ++var5) {
String key = var3[var5];
keySet.addAll(this.redisTemplate.keys(key));
}
long count = this.redisTemplate.delete(keySet);
log.info("--------------------------------------------");
log.info("成功删除缓存:" + keySet);
log.info("缓存删除数量:" + count + "个");
log.info("--------------------------------------------");
}
}
}
public Object get(String key) {
return key == null ? null : this.redisTemplate.opsForValue().get(key);
}
public boolean set(String key, Object value, long time, TimeUnit timeUnit) {
try {
if (time > 0L) {
this.redisTemplate.opsForValue().set(key, value, time, timeUnit);
} else {
this.set(key, value);
}
return true;
} catch (Exception var7) {
log.error(var7.getMessage(), var7);
return false;
}
}
public Map<Object, Object> hmget(String key) {
return this.redisTemplate.opsForHash().entries(key);
}
public boolean hset(String key, String item, Object value) {
try {
this.redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception var5) {
log.error(var5.getMessage(), var5);
return false;
}
}
public void hdel(String key, Object... item) {
this.redisTemplate.opsForHash().delete(key, item);
}
public boolean hHasKey(String key, String item) {
return this.redisTemplate.opsForHash().hasKey(key, item);
}
public Long increment(String key) {
return this.redisTemplate.opsForValue().increment(key);
}
}
调用时直接使用 snowflakeIdGenerator.nextId() 即可
数据实时同步过滤
问题描述
最近发现业务系统在执行任务同步时,无法有效过滤配置后的数据类型,具体表现在:
1、数据同步分为手动同步、实时同步、全量推送,手动和全量因为是在具体的同步任务上触发的,可以根据任务id查询绑定的配置信息
2、原始的实时同步逻辑,是在确定不是其他同步的前提下,根据实时同步的数据类型,筛出同步相应数据的多个任务,直接推送
3、因为针对任务配置,调整数据范围的操作,在推送前已经发生了,第2步多个同步任务的配置没有生效
(可以理解成大类数据,存在多个数据标签,任务配置了相应数据类型、数据标签的范围)
解决方案
在第二步确定不是其他同步后,标记当前同步类型(Flag),后续在筛出符合的多个同步任务后,根据标记,每次推送时再次根据任务配置过滤(不同任务的配置的数据标签不一样)
dive分析镜像
问题描述
最近部分业务功能打包的镜像过大,需要对docker打包的过程进行分析,查看对应的 dockerfile 文件很容易判断出层数,但我想更精确点,最好有详细说明及大小增加信息。
解决方案
首先拉取 dive 镜像(如果已经拉取过可以跳过)
1
docker pull wagoodman/dive
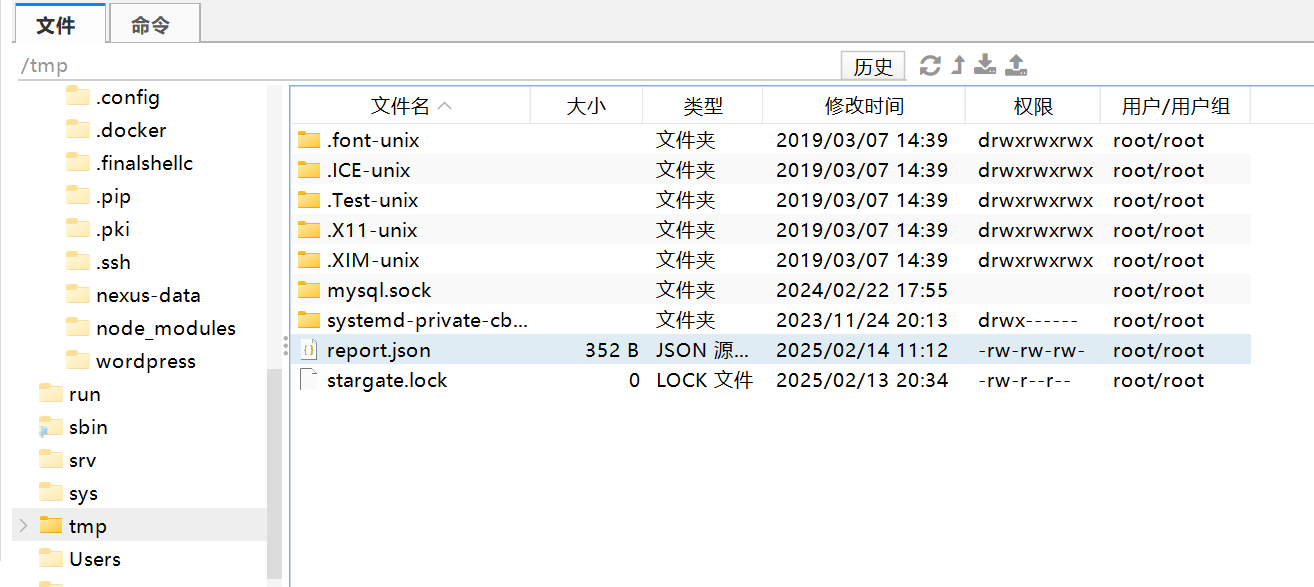
先创建文件并设置权限(保证第三步导出的文件在服务器的/tmp目录下,且名字为report.json)
1
2touch /tmp/report.json
chmod 666 /tmp/report.json
- 然后运行 dive 分析并写入
1
docker run --rm -v /var/run/docker.sock:/var/run/docker.sock -v /tmp/report.json:/report.json wagoodman/dive:latest hello-world --json /report.json
从服务器的 /tmp/report.json 中读取分析结果即可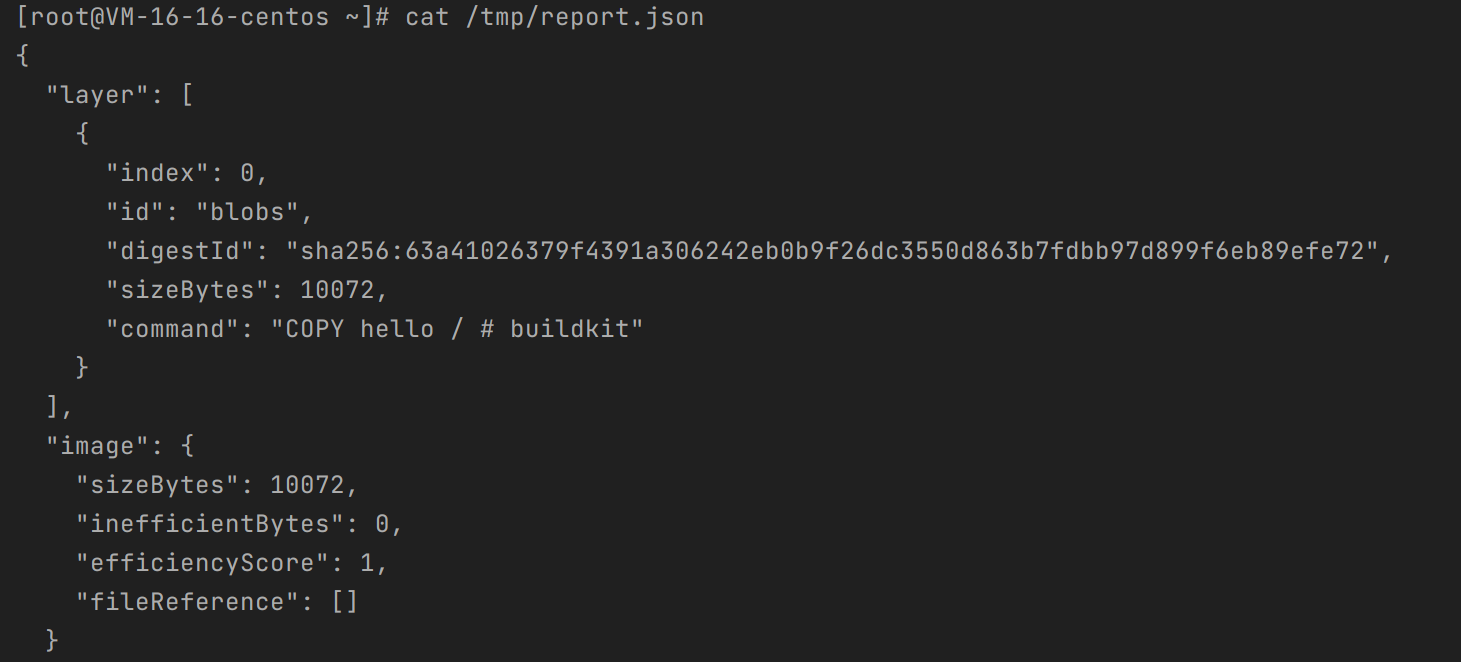
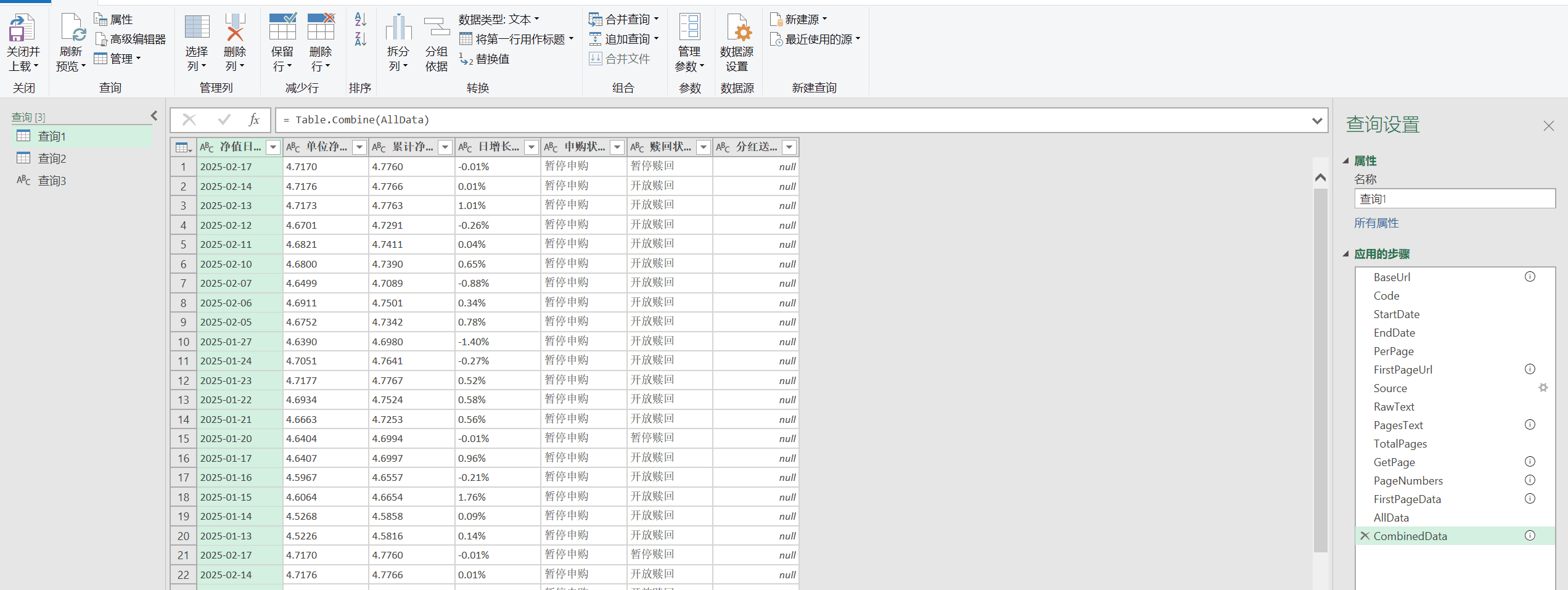
天天基金网获取基金历史净值数据
问题描述
年前标普500基金回调,想着加仓一波,但是许多产品都限购,只能从对应的基金App买,这就导致我在支付宝和基金App购买的记录无法互通,就想着拿到基金所有的净值数据,将两个平台的购买记录手动记录下,方便后续统计。
今年一定去开港卡,天王老子来了也拦不住我!!!!
解决方案
我知道Excel中有对应从其他数据源导入的功能,将具体需求描述给claude后,得到了如下方案:
新建excel文件,通过”数据-> 新建查询 -> 从其他源 -> 空白查询”进入对应页面

点击高级编辑器按钮,粘贴对应代码并运行,查看结果
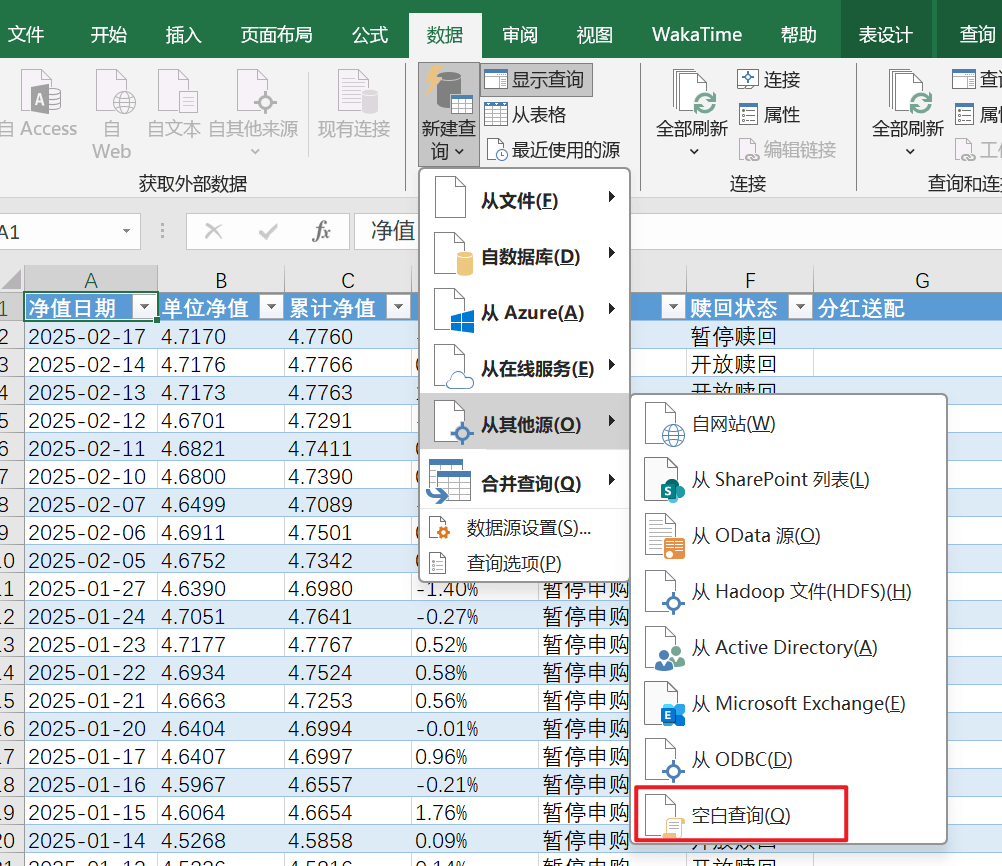
1 | let |
我将起始日期设置为2001年1月1日,保证能抓取所有的净值记录,结束日期设置为函数获取的当前日期,页码数是根据总数动态赋值的,只需要修改对应的基金代码(也就是 Code = "050025" 这一行)就能用。